Nemesis AI
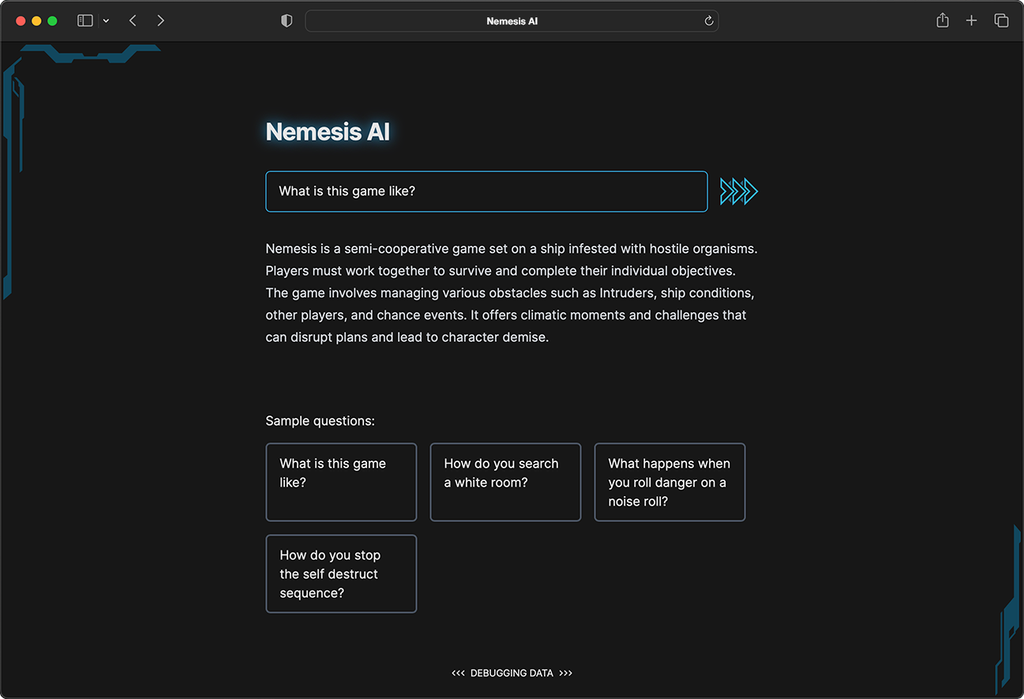
Nemesis AI is a bot that I built to answer questions about the rules of the board game Nemesis .
The project is a two-part system: the Python scripts that build an index from the rules of the game, and the Next.js app that provides the interface and feeds GPT the parts of the index it needs to answer user questions.
Created with
- Python
- Langchain
- OpenAI API
- React
- Next.js
- Tailwind CSS
Motivation and purpose
The rise of new AI tools has been wild and exciting, and I've had fun exploring different corners of the programming world and finding new things to bring into web development.
One of the first things I tried to build was a chatbot with a custom knowledge base. I started by using GPT Index, (now known as Llama index) which is a library that does most of the heavy lifting in creating an index from your data and then querying it. I tried it out with a collection of markdown files containing blog post content, but there was a lot going on behind the scenes that I didn’t understand. I struggled through a couple smaller projects where I did everything from scratch, which helped me learn the mechanisms way better. I refined my techniques over a few different iterations of question-answering systems, and after building this app, I feel more confident going back and learning the more robust tooling out there. I better understand the tradeoffs of different ones, and can make more informed decisions about which to use for different situations.

Features
The format of the system is a single question and answer, as is pretty common for tools like those that let you ask questions about a podcast series or YouTube channel. This keeps the UI simple and the text generation output more predictable, but with GPT it’s possible to implement a continuous conversation as well.
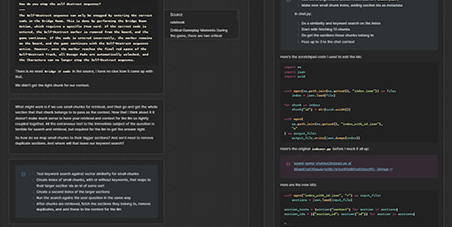
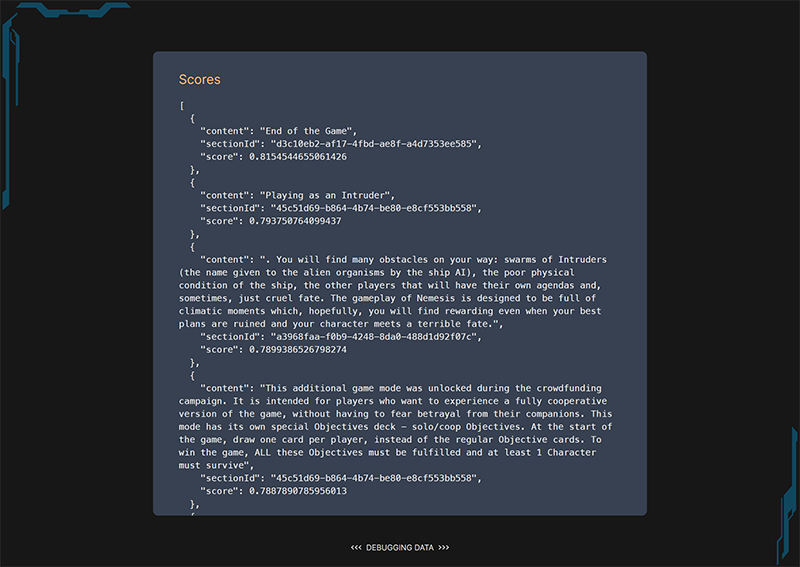
One extra thing I added for my own sanity was a debugging log. During development I quickly found that debugging LLM inputs and outputs was a whole different beast than debugging I had done for any kind of project I'd done before. The logs usually consist of large amounts of text that are hard to parse at a glance, and the outputs aren’t deterministic. I added a little modal that logs out the data for the current answer. It shows the parts of the source material that matched the similarity search, as well as the sections that were sent to the API as context for the answer.
Challenges
I ran headlong into the ever-persistent problem of LLMs: accuracy. The process of question-answering with a custom knowledge base at its most basic is straightforward, but the results can be all over the place and it can be extremely difficult to get consistent, accurate answers.
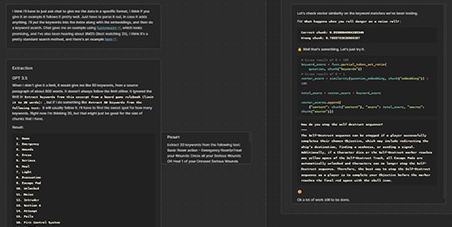
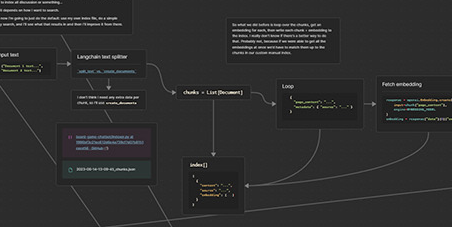
I had some difficulty with the common method of retrieval where you use a similarity search to retrieve chunks from your index, and feed some number of those to the completion model. At first I was having trouble retrieving the right information from the source material. I needed to have it split into large chunks, to include enough surrounding context, but the retrieval method works by selecting chunks based on how similar they are to the user’s question. Such large chunks meant that lots of them matched the question just as well as others that were more relevant. So I did an extra retrieval step: I made the chunks small enough that I would get the most relevant ones, and then I retrieved the larger sections that those chunks came from. This helped my retrieval accuracy and context quality immensely.
Documenting the process
I’ve grown more and more enthusiastic about keeping notes as I work on a project, especially since I've discovered Obsidian and its Canvas feature, which lets you lay out blocks of content any way you like. On this project I tried to really go over the top, keeping daily logs of working through my objectives and thought processes. As of now I don't know whether it's a better system than traditional linear notes, but there are a lot of opportunities for improvement to explore.